Ejemplo de Time Series Data y CompletableFuture en Java
El código completo de todos los ejemplos se encuentra aquí.
Cómo ejecutar el programa
mvn clean compile verify exec:javaPrefacio
Supongamos que queremos calcular un índice de calidad del aire basado en dos valores:
- temperatura del aire
- porcentaje de monóxido de carbono en el aire
Dados los siguientes símbolos:
| símbolo | significado |
|---|---|
AQi | índice de calidad del aire |
T | temperatura del aire en grados Celsius |
Tm | temperatura máxima del aire en C° |
C | porcentaje de monóxido de carbono en el aire |
Podemos calcular el AQi con esta especie de fórmula:
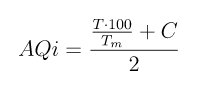
DISCLAIMER: esta fórmula no es de ninguna manera científica y está pensada exclusivamente con fines educativos. No quiero que ambientalistas y científicos de verdad me persigan con fórmulas matemáticas y acusaciones de charlatanería. Además, vi la oportunidad de crear una bonita ecuación en LaTeX y la aproveché, por motivos estéticos y porque me hace parecer inteligente, cosa que ciertamente no soy1.
Lo que la fórmula intenta expresar es que al subir la temperatura y el porcentaje de monóxido de carbono, la calidad del aire decrece. Sí, esto es totalmente anticientífico pero veréis que tiene sentido a efectos de mi argumentación.
Asumo una temperatura máxima de 40C°. Así que, por ejemplo:
$ bc -l
bc 1.06
Copyright 1991-1994, 1997, 1998, 2000 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type 'warranty'.
t=60; c=100; tm=40; (((t * 100) / tm) + c) / 2
125.00000000000000000000
t=60; c=50; tm=40; (((t * 100) / tm) + c) / 2
100.00000000000000000000
t=40; c=50; tm=40; (((t * 100) / tm) + c) / 2
75.00000000000000000000
t=40; c=10; tm=40; (((t * 100) / tm) + c) / 2
55.00000000000000000000
t=20; c=10; tm=40; (((t * 100) / tm) + c) / 2
30.00000000000000000000
t=10; c=5; tm=40; (((t * 100) / tm) + c) / 2
15.00000000000000000000
t=10; c=0.5; tm=40; (((t * 100) / tm) + c) / 2
12.75000000000000000000De esto podemos derivar la siguiente tabla totalmente anticientífica:
| AQi | significado |
|---|---|
| de 125 a ∞ | muerte horrible |
| de 100 a 125 | muerte dolorosa |
| de 75 a 100 | muerte |
| de 55 a 75 | es aceptable2 |
| de 30 a 55 | todo bien3 |
| de 15 a 30 | se está bien |
| de 12.75 a 15 | fresquito |
| de -∞ a 12.75 | bienvenido a Yakutsk, probablemente |
Proveedores de servicios
Supongamos que tenemos servicios de internet que exponen datos de monitorización de temperatura y niveles de monóxido de carbono. Estos servicios podrían exponer una API que nos proporciona datos de tipo time series4.
Así, por ejemplo, podríamos llamar a un servicio de monitorización de temperatura, y el servicio nos respondería con datos time series como estos:
| timestamp | valor |
|---|---|
2021-01-20T08:00:00Z | 10.1 |
2021-01-20T08:02:00Z | 10.3 |
2021-01-20T08:05:00Z | 10.7 |
2021-01-20T08:06:00Z | 10.9 |
2021-01-20T08:06:19Z | 11.0 |
2021-01-20T08:06:42Z | 11.1 |
2021-01-20T08:09:00Z | 11.3 |
Un servicio de monitorización de porcentaje de monóxido de carbono podría en cambio responder con datos como estos:
| timestamp | valor |
|---|---|
2021-01-20T08:01:00Z | 2.0 |
2021-01-20T08:02:00Z | 2.3 |
2021-01-20T08:06:00Z | 2.8 |
2021-01-20T08:07:00Z | 2.9 |
2021-01-20T08:08:00Z | 3.3 |
Ten en cuenta que he ordenado los datos por timestamp para hacerlos un poco más legibles, pero no deberías asumir nada sobre el orden de los datos devueltos por un proveedor externo. No es que esto tenga importancia aquí porque...
El algoritmo
...nuestro algoritmo ahora requiere:
- concatenar los datos de temperatura y porcentaje de monóxido de carbono
- ordenar por timestamp
| id | timestamp | valor | tipo |
|---|---|---|---|
1 | 2021-01-20T08:00:00Z | 10.1 | T |
2 | 2021-01-20T08:01:00Z | 2.0 | C |
3 | 2021-01-20T08:02:00Z | 10.3 | T |
4 | 2021-01-20T08:02:00Z | 2.3 | C |
5 | 2021-01-20T08:05:00Z | 10.7 | T |
6 | 2021-01-20T08:06:00Z | 10.9 | T |
7 | 2021-01-20T08:06:00Z | 2.8 | C |
8 | 2021-01-20T08:06:19Z | 11.0 | T |
9 | 2021-01-20T08:06:42Z | 11.1 | T |
10 | 2021-01-20T08:07:00Z | 2.9 | C |
11 | 2021-01-20T08:08:00Z | 3.3 | C |
12 | 2021-01-20T08:09:00Z | 11.3 | T |
tipo: T es temperatura y C es porcentaje de monóxido de carbono
Nuestra tarea ahora es recorrer los datos, empezando desde el principio, una fila a la vez, calculando el índice de calidad del aire a medida que avanzamos, paso a paso.
Lo primero que hay que notar aquí es que para calcular nuestra fórmula del AQi
necesitamos tener ambos valores para T y C. En otras palabras, el primer
punto en el que podemos aplicar nuestra fórmula es el del id 2, ya que tenemos
un valor para T en el id 1 y un valor para C en el id 2. Así que
tomamos nuestros valores (10.1 para T y 2.0 para C), aplicamos la
fórmula, y obtenemos un primer valor de AQi de 13.625 que asociamos con el
timestamp del id 2, ya que ese es el momento al que se refiere nuestro
cálculo. Nuestra primera entrada de AQi en la serie resultante debería verse
así:
| timestamp | valor |
|---|---|
2021-01-20T08:01:00Z | 13.625 |
De ahora en adelante, nuestra fórmula puede aplicarse a cada elemento restante en la serie, teniendo en cuenta que debemos correlacionar cada valor con el valor más reciente del otro tipo. En otras palabras:
| para el id | tomar valores de los id |
|---|---|
2 | 1, 2 |
3 | 2, 3 |
4 | 3, 4 |
5 | 4, 5 |
6 | 4, 6 |
7 | 6, 7 |
8 | 7, 8 |
9 | 7, 9 |
10 | 9, 10 |
11 | 9, 11 |
12 | 11, 12 |
Esta técnica se conoce como last-value carry-forward (a veces llamada as-of join): para cada nuevo dato, miramos hacia atrás y tomamos el valor más reciente de cada tipo visto hasta ahora. A medida que avanzamos en la línea temporal, siempre emparejamos la lectura actual con el último valor disponible del otro tipo5.
Last-Value Carry-Forward
Adelante, desplázate hacia abajo. Deberías verla.
Step 01: T = 10.1, C = 2.0, AQi = 13.625
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 1, 2
Step 02: T = 10.3, C = 2.0, AQi = 13.875
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 2, 3
Step 03: T = 10.3, C = 2.3, AQi = 14.025
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 3, 4
Step 04: T = 10.7, C = 2.3, AQi = 14.525
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 4, 5
Step 05: T = 10.9, C = 2.3, AQi = 14.775
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 4, 6
Step 06: T = 10.9, C = 2.8, AQi = 15.025
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 6, 7
Step 07: T = 11.0, C = 2.8, AQi = 15.150
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 7, 8
Step 08: T = 11.1, C = 2.8, AQi = 15.275
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 7, 9
Step 09: T = 11.1, C = 2.9, AQi = 15.325
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 9, 10
Step 10: T = 11.1, C = 3.3, AQi = 15.525
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 9, 11
Step 11: T = 11.3, C = 3.3, AQi = 15.775
| id | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | 10.1 | 10.3 | 10.7 | 10.9 | 11.0 | 11.1 | 11.3 | |||||
| C | 2.0 | 2.3 | 2.8 | 2.9 | 3.3 |
Carry-forward: id 11, 12
Dado lo anterior, nuestra serie temporal completa para el AQi es:
| timestamp | valor |
|---|---|
2021-01-20T08:01:00Z | 13.625 |
2021-01-20T08:02:00Z | 13.875 |
2021-01-20T08:02:00Z | 14.025 |
2021-01-20T08:05:00Z | 14.525 |
2021-01-20T08:06:00Z | 14.775 |
2021-01-20T08:06:00Z | 15.025 |
2021-01-20T08:06:19Z | 15.150 |
2021-01-20T08:06:42Z | 15.275 |
2021-01-20T08:07:00Z | 15.325 |
2021-01-20T08:08:00Z | 15.525 |
2021-01-20T08:09:00Z | 15.775 |
Si has mirado con atención, habrás notado que tenemos un par de timestamps
duplicados en los resultados, concretamente 2021-01-20T08:02:00Z y
2021-01-20T08:06:00Z. Estos representan una paradoja temporal ya que parece
que nuestro AQi tiene dos valores diferentes en el mismo instante.

Ambos sabemos que estos datos van a acabar en una página web. No querrás que uno de esos desarrolladores hipster del frontend nos señale una falta de lógica o, peor aún, una inconsistencia en nuestros datos, ¿verdad?
Eso pensaba. Pues bien, mi idea es que podemos descartar tranquilamente la
primera entrada de un timestamp duplicado ya que se refiere a un cálculo con
datos obsoletos. ¿Por qué? Bueno, considera los valores del primer timestamp
duplicado: 2021-01-20T08:02:00Z. La primera vez que calculamos el AQi,
tomamos los datos de los id 2 y 3 y el id 2 se refiere a un timestamp
anterior, concretamente 2021-01-20T08:01:00Z. La segunda vez que calculamos el
AQi, usamos los datos de los id 3 y 4, que se refieren ambos al timestamp
2021-01-20T08:02:00Z, por lo que el resultado de este cálculo es más relevante
que el anterior para el que produjimos el mismo timestamp de
2021-01-20T08:02:00Z.
Lo mismo se aplica a la entrada del AQi con timestamp 2021-01-20T08:06:00Z
ya que el primer cálculo usaba los id 4 y 6 mientras que el segundo
consideraba los id 6 y 7 que son más recientes que el timestamp del id 4.
Así que eliminamos un par de entradas y nuestro resultado limpio queda así:
| timestamp | valor |
|---|---|
2021-01-20T08:01:00Z | 13.625 |
2021-01-20T08:02:00Z | 14.025 |
2021-01-20T08:05:00Z | 14.525 |
2021-01-20T08:06:00Z | 15.025 |
2021-01-20T08:06:19Z | 15.150 |
2021-01-20T08:06:42Z | 15.275 |
2021-01-20T08:07:00Z | 15.325 |
2021-01-20T08:08:00Z | 15.525 |
2021-01-20T08:09:00Z | 15.775 |
Igual que una ecuación es una buena excusa para repasar un poco de LaTeX, una buena serie de datos temporales es un excelente candidato para gnuplot.
Los datos en el mundo real son, por supuesto, mucho más caóticos que esto, y podrías querer normalizar el resultado usando un intervalo temporal arbitrario, por ejemplo un minuto:
| timestamp | valor |
|---|---|
2021-01-20T08:01:00Z | 13.625 |
2021-01-20T08:02:00Z | 14.025 |
2021-01-20T08:03:00Z | 14.025 |
2021-01-20T08:04:00Z | 14.025 |
2021-01-20T08:05:00Z | 14.525 |
2021-01-20T08:06:00Z | 15.025 |
2021-01-20T08:07:00Z | 15.325 |
2021-01-20T08:08:00Z | 15.525 |
2021-01-20T08:09:00Z | 15.775 |
¿Tiene sentido? Espero que sí.

Escribamos el código
Escribamos algo de código. Primero, definamos una interfaz para nuestro
calculador de AQi, para poder proporcionar diferentes implementaciones más
adelante.
El código de esta interfaz se puede ver aquí.
La interfaz es un lugar conveniente donde implementar la fórmula del AQi:
static double airQualityIndex(double temperature, double carbonMonoxidePercentage, double maxTemperature) {
return (((temperature * 100) / maxTemperature) + carbonMonoxidePercentage) / 2;
}Este método toma una temperatura, un porcentaje de monóxido de carbono, una
temperatura máxima y devuelve el AQi. Bien.
La parte interesante sin embargo es este método:
List<TimeValue> calculate(List<TimeValue> temperatures, List<TimeValue> carbonMonoxidePercentages);Esto nos dice que el método calculate toma dos listas de TimeValue: la
primera es una lista de temperaturas y la otra es una lista de porcentajes de
monóxido de carbono. Luego devuelve una lista de TimeValue, solo que esta vez
la lista representa los índices de calidad del aire.
¿Qué es un TimeValue? Podemos ver su definición
aquí.
Aunque todo esto parece horriblemente complicado debido a la verbosidad del
lenguaje Java y algunos detalles de implementación, puedes pensar en un
TimeValue como una forma cómoda de representar un Instant en el tiempo y su
valor asociado. Nada del otro mundo, realmente.
Programar como si fuera 1984
Ahora que tenemos un framework básico para nuestros cálculos, escribamos una primera implementación usando el estilo vieja escuela. El código completo está aquí. Echémosle un vistazo.
Nuestro calculador toma la temperatura máxima en su constructor y almacena su
valor en la constante de instancia maxTemperature ya que necesitaremos su
valor más adelante cuando invoquemos la función del AQi.
Nuestro método calculate debe comenzar con estos dos pasos:
- concatenar los datos de temperatura y porcentaje de monóxido de carbono en una sola estructura de datos
- ordenar el resultado por timestamp
El primer paso está implementado en este bloque de código:
// key = time value type (C = carbonMonoxidePercentage, T = temperature)
// concatenated with the timestamp as a string
Map<String, TimeValue> timeValuesByType = new HashMap<>();
for (TimeValue temperature : temperatures) {
timeValuesByType.put("T".concat(temperature.ts()), temperature);
}
for (TimeValue carbonMonoxidePercentage : carbonMonoxidePercentages) {
timeValuesByType.put("C".concat(carbonMonoxidePercentage.ts()), carbonMonoxidePercentage);
}La clave en nuestra variable timeValuesByType es una concatenación en cadena
de la letra T para temperatura o C para porcentaje de monóxido de carbono,
seguida del timestamp. Necesitamos hacer esto para poder luego distinguir entre
los dos tipos de datos. Las cadenas de la clave tendrán este aspecto:
T2021-02-03T08:00:00.000Z.
El ordenamiento se realiza en este bloque:
Map<String, TimeValue> timeValuesByTypeSortedByTimestamp = new LinkedHashMap<>();
List<String> keysSortedByTimestamp = new ArrayList<>(timeValuesByType.keySet());
keysSortedByTimestamp.sort(comparing(s -> timeValuesByType.get(s).timestamp()));
for (String key : keysSortedByTimestamp) {
timeValuesByTypeSortedByTimestamp.put(key, timeValuesByType.get(key));
}Esto es solo la forma supercomplicada de Java para ordenar nuestro mapa según el
timestamp que tenemos en los valores del mapa. Declaramos un mapa
timeValuesByTypeSortedByTimestamp, implementado por un LinkedHashMap porque
queremos preservar el orden de iteración de las entradas del mapa. Luego
envolvemos todas las claves de nuestro mapa original timeValuesByType en un
ArrayList ya que necesitamos una List para poder invocar sort. La función de
comparación que pasamos a sort toma el timestamp de la entrada relativa en el
mapa original timeValuesByType. Luego iteramos keysSortedByTimestamp,
añadiendo entradas a nuestro mapa timeValuesByTypeSortedByTimestamp.
Ahora declaramos un mapa para los resultados de nuestros cálculos del AQi y
un par de variables que necesitaremos después:
Map<Instant, Double> airQualityIndexMap = new HashMap<>();
TimeValue lastTemperature = null;
TimeValue lastCarbonMonoxidePercentage = null;Aquí empieza la parte divertida. Recorremos las entradas del mapa en nuestra
variable timeValuesByTypeSortedByTimestamp previamente definida.
for (Map.Entry<String, TimeValue> entry : timeValuesByTypeSortedByTimestamp.entrySet()) {
...Sabemos que si la clave empieza con una T, tenemos un valor de temperatura y,
en tal caso, lo almacenamos en la variable lastTemperature. De lo contrario,
el valor debe ser de tipo C para carbono, así que hacemos lo mismo con la
variable lastCarbonMonoxidePercentage.
if (entry.getKey().startsWith("T")) {
lastTemperature = entry.getValue();
} else if (entry.getKey().startsWith("C")) {
lastCarbonMonoxidePercentage = entry.getValue();
}En este punto, si tenemos un valor tanto para T como para C, podemos
proceder a calcular nuestro AQi y almacenar su valor en la variable
airQualityIndexMap.
if (lastTemperature != null && lastCarbonMonoxidePercentage != null) {
airQualityIndexMap.put(
mostRecent(lastTemperature.timestamp(), lastCarbonMonoxidePercentage.timestamp()),
airQualityIndex(lastTemperature.value(), lastCarbonMonoxidePercentage.value(), maxTemperature)
);
}Estamos tomando el timestamp más reciente entre los dos TimeValue usando una
pequeña función auxiliar que definimos anteriormente en la interfaz del
calculador.
Un efecto colateral deseado de usar un mapa para esta estructura de datos es que, cuando insertamos un nuevo valor para un timestamp existente, la entrada se sobrescribe con el más reciente. Esto resuelve nuestro problema con los timestamps duplicados.
Al final del ciclo, nuestros resultados están casi listos. Solo necesitamos
ordenarlos de nuevo por timestamp y devolver los valores como una List de
TimeValue.
List<Instant> keys = new ArrayList<>(airQualityIndexMap.keySet());
keys.sort(Instant::compareTo);
List<TimeValue> results = new ArrayList<>();
for (Instant key : keys) {
results.add(TimeValue.of(key, airQualityIndexMap.get(key)));
}Elegancia funcional
¿Podemos hacerlo mejor? Por supuesto. Usemos un arma elegante para tiempos más civilizados: la programación funcional. Nuestro FunctionalAirQualityIndexCalculator está reducido casi al mínimo, pero eso es solo porque la lógica principal detrás de los cálculos ahora se encuentra en el AirQualityIndexCollector.
Nuestro nuevo calculador es mucho más simple ahora. La primera parte es un poco compleja así que veámosla primero:
List<TypedTimeValue> timeSeries = Stream.concat(
temperatures.stream().map(e -> new TypedTimeValue(TypedTimeValue.Type.T, e)),
carbonMonoxidePercentages.stream().map(e -> new TypedTimeValue(TypedTimeValue.Type.C, e))
).collect(Collectors.toUnmodifiableList());Hay varios patrones funcionales trabajando aquí:
-
los datos de temperatura y porcentaje de monóxido de carbono se transmiten y mapean en un contenedor de tipo para poder luego entender si el dato que estamos mirando es de tipo
ToC -
los dos streams resultantes se concatenan usando
Stream.concat -
al final recolectamos el stream concatenado en una
List<TypedTimeValue>no modificable
return timeSeries.stream().parallel()
.collect(AirQualityIndexCollector.toUnmodifiableList(maxTemperature));La variable timeSeries se transmite entonces en paralelo a un colector que
hace el trabajo pesado y devuelve una List<TimeValue> no modificable con los
índices de calidad del aire.
Echemos un vistazo al colector.
public class AirQualityIndexCollector
implements Collector<TypedTimeValue, Queue<TypedTimeValue>, List<TimeValue>> {
...Estamos implementando la interfaz Collector. Los parámetros de tipo que
proporcionamos expresan tres cosas:
- estamos recolectando valores de tipo
TypedTimeValue - nuestro acumulador interno usa una
Queue<TypedTimeValue> - al final del trabajo, devolvemos una
List<TimeValue>
Usamos una Queue porque ConcurrentLinkedQueue nos ofrece una colección
thread-safe para acumular valores durante el procesamiento paralelo de streams.
Proporcionamos la implementación usando el método supplier:
@Override
public Supplier<Queue<TypedTimeValue>> supplier() {
return ConcurrentLinkedQueue::new;
}En este caso, la implementación es una ConcurrentLinkedQueue que nos garantiza
inserciones thread-safe durante el procesamiento paralelo.
@Override
public BiConsumer<Queue<TypedTimeValue>, TypedTimeValue> accumulator() {
return Queue::add;
}El acumulador debe devolver una función que el colector usa para acumular los
datos de entrada. Como puedes ver, simplemente devolvemos una referencia al
método add de Queue.
@Override
public BinaryOperator<Queue<TypedTimeValue>> combiner() {
return (typedTimeValues, typedTimeValues2) -> {
typedTimeValues.addAll(typedTimeValues2);
return typedTimeValues;
};
}El método combiner debe devolver una función que combina dos acumuladores. La
implementación debe tomar todos los elementos del segundo acumulador y añadirlos
al primero, lo cual no suena muy funcional en términos de inmutabilidad pero en
este caso es un comportamiento esperado, y está perfectamente bien.
@Override
public Function<Queue<TypedTimeValue>, List<TimeValue>> finisher() {
...Finalmente, el finisher debe devolver una función que toma todos los valores
acumulados en nuestra Queue<TypedTimeValue> y devuelve una List<TimeValue>
con nuestros índices de calidad del aire.
final Map<Instant, TimeValue> aqiAccumulator = new HashMap<>();Este es un mapa que sirve para recolectar los índices de calidad del aire. Como puedes ver, está indexado por timestamp, así que no tendremos entradas duplicadas cuando cálculos más recientes para un mismo timestamp se inserten en el mapa reemplazando los anteriores.
return accumulator -> {
accumulator.stream()
.map(TypedTimeValue::timestamp)
.sorted()
.forEach(entryTS -> {
final TimeValue lastTemperature = getClosest(accumulator, TypedTimeValue.Type.T, entryTS);
final TimeValue lastCarbonMonoxidePercentage = getClosest(accumulator, TypedTimeValue.Type.C, entryTS);
if (lastTemperature != null && lastCarbonMonoxidePercentage != null) {
Instant timestamp = mostRecent(lastTemperature.timestamp(), lastCarbonMonoxidePercentage.timestamp());
aqiAccumulator.put(timestamp, TimeValue.of(timestamp, airQualityIndex(lastTemperature.value(), lastCarbonMonoxidePercentage.value(), maxTemperature)));
}
});
return aqiAccumulator.values().stream()
.sorted()
.collect(Collectors.toUnmodifiableList());
};Esto es un buen bloque de código pero veámoslo poco a poco. Estamos transmitiendo los datos acumulados, extrayendo el timestamp, ordenando por este y, para cada timestamp, buscamos los datos de temperatura y porcentaje de monóxido de carbono con el timestamp más cercano. Más cercano significa que el timestamp que estamos evaluando debe ser anterior o igual al timestamp en cuestión.
Si tenemos ambos datos (T y C), podemos proceder al cálculo del AQi y
poner su valor en el mapa aqiAccumulator.
Finalmente, todo lo que tenemos que hacer es tomar los valores del mapa
aqiAccumulator, ordenarlos por timestamp y recolectarlos en una
List<TimeValue> no modificable.
El ordenamiento es posible gracias a que nuestra clase TimeValue implementa
Comparable<TimeValue>.
Hay varios puntos en el método finisher donde miro dentro de las estructuras
de datos sobre las que estoy iterando, lo cual, de nuevo, no parece muy kosher
en términos de programación funcional, pero está bien porque sé que los datos
que estoy examinando no son susceptibles de ser modificados entre bastidores por
threads concurrentes.
¿Es este calculador mejor que el de la vieja escuela? No estoy seguro. Esto sigue siendo bastante verboso, pero me parece más fácil de leer ya que gran parte del código está escrito en un estilo declarativo en lugar de imperativo.
Consideraciones sobre la concurrencia
Como necesitamos recuperar dos conjuntos de datos diferentes de dos proveedores distintos (uno para los datos de temperatura y otro para los datos de porcentaje de monóxido de carbono), podríamos querer ejecutar los clientes en paralelo. Esto tiene una ventaja sobre la ejecución en un solo hilo donde tendrías que serializar las llamadas a los proveedores.
En un entorno de un solo hilo, podrías escribir:
TimeValueProvider providerT = new TemperatureTimeValueProvider();
TimeValueProvider providerC = new CarbonMonoxidePercentageProvider();
List<TimeValue> timeValuesT = providerT.get();
List<TimeValue> timeValuesC = providerC.get();Esto se traduce en el siguiente modelo de ejecución serial:
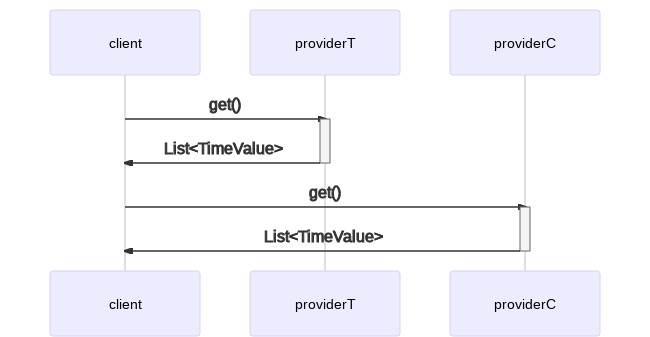
Como dijimos, podemos hacerlo mejor. En un entorno multihilo, podemos lanzar dos clientes concurrentes y comenzar el procesamiento de los datos en cuanto recibamos respuesta de ambos. Esto nos ahorra algo de tiempo y potencialmente acelera nuestros tiempos de respuesta.
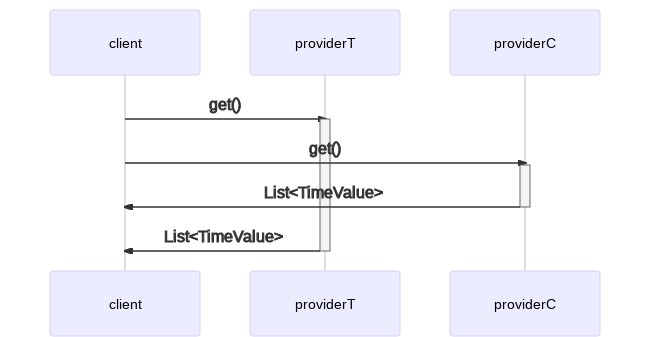
¿Cómo implementamos este modelo de ejecución en nuestro código? Hay varias
opciones, pero la más popular, y la que personalmente prefiero, es usar
CompletableFuture, que fueron introducidos en Java 8, si no recuerdo mal.
Un CompletableFuture es un contenedor para una computación. Le proporcionas el
código que quieres ejecutar y el runtime de Java se encarga de ejecutarlo en
concurrencia en un scheduler multihilo. El scheduler es, por supuesto,
configurable pero los valores por defecto están bien para nuestro caso. Puedes
ver el ejemplo completo
aquí.
En mi ejemplo he declarado mis CompletableFuture así:
CompletableFuture<List<TimeValue>> timedValuesFuture1 = CompletableFuture.supplyAsync(() -> {
log("Calling provider1...");
List<TimeValue> timeValues = provider1.get();
log(String.format("provider 1 returned: %s\n", timeValues));
return timeValues;
});Esto es un poco verboso ya que quería incluir algunos logs para mostrar cómo el código se ejecuta en paralelo. Podría haber escrito simplemente:
CompletableFuture<List<TimeValue>> timedValuesFuture1 = CompletableFuture.supplyAsync(provider1::get);Esto sigue siendo verboso pero definitivamente mejor que antes. Como la
computación en nuestro CompletableFuture devuelve una List<TimeValue>, el
método supplyAsync devuelve un CompletableFuture<List<TimeValue>>, que es la
forma de Java de decir que la variable timedValuesFuture1 es un
CompletableFuture que contiene una List<TimeValue>. Ten en cuenta que el
código que estamos pasando al método supplyAsync está dentro de una lambda.
Esto significa que nuestro código no se ejecuta en el método supplyAsync sino
que el runtime de Java es libre de elegir el mejor momento para ejecutarlo. El
scheduler por defecto generalmente iniciará los CompletableFuture tan pronto
como se definan, pero debes saber que no es necesariamente así y que definir una
lambda no significa que se ejecute en el punto de declaración.
Ahora necesitamos una forma de asegurarnos de que nuestros CompletableFuture
hayan terminado su ejecución antes de poder continuar. Esto se hace componiendo
los futures y llamando al método join sobre el future resultante:
CompletableFuture.allOf(timedValuesFuture1, timedValuesFuture2).join();El método allOf devuelve un nuevo CompletableFuture que envuelve los futures
que le estamos pasando. Sobre este nuevo future llamamos join que bloquea la
ejecución hasta que todos los futures internos hayan terminado su trabajo.
Después de esta línea estamos seguros de que nuestros threads se han ejecutado,
así que podemos obtener los datos que necesitamos de nuestros futures originales
usando el método join:
List<TimeValue> timeValues1 = timedValuesFuture1.join();
List<TimeValue> timeValues2 = timedValuesFuture2.join();Ejemplo de output
Cuando ejecutes la aplicación, deberías ver un output similar a este:
2021-02-03T17:50:26.772545406 --- [main] Hello concurrent world!
2021-02-03T17:50:26.801737530 --- [ForkJoinPool.commonPool-worker-3] Calling provider1...
2021-02-03T17:50:26.802105151 --- [main] Calling allOf(...).join()
2021-02-03T17:50:26.802202415 --- [ForkJoinPool.commonPool-worker-5] Calling provider2...
2021-02-03T17:50:27.834127796 --- [ForkJoinPool.commonPool-worker-5] provider 2 returned: [TimeValue{timestamp=2021-01-18T08:00:22Z, value=76.629}, TimeValue{timestamp=2021-01-18T08:00:45Z, value=90.241}]
2021-02-03T17:50:27.834702562 --- [ForkJoinPool.commonPool-worker-3] provider 1 returned: [TimeValue{timestamp=2021-01-18T08:00:24Z, value=30.318}, TimeValue{timestamp=2021-01-18T08:00:35Z, value=13.521}, TimeValue{timestamp=2021-01-18T08:00:35Z, value=29.518}, TimeValue{timestamp=2021-01-18T08:00:36Z, value=0.818}, TimeValue{timestamp=2021-01-18T08:00:46Z, value=8.695}, TimeValue{timestamp=2021-01-18T08:00:50Z, value=31.233}, TimeValue{timestamp=2021-01-18T08:00:51Z, value=24.675}, TimeValue{timestamp=2021-01-18T08:00:53Z, value=38.477}]
2021-02-03T17:50:27.835040844 --- [main] After allOf(...).join()
2021-02-03T17:50:27.852793190 --- [main] timeValues = [TimeValue{timestamp=2021-01-18T08:00:24Z, value=76.212}, TimeValue{timestamp=2021-01-18T08:00:35Z, value=75.212}, TimeValue{timestamp=2021-01-18T08:00:36Z, value=39.337}, TimeValue{timestamp=2021-01-18T08:00:45Z, value=46.143}, TimeValue{timestamp=2021-01-18T08:00:46Z, value=55.989}, TimeValue{timestamp=2021-01-18T08:00:50Z, value=84.161}, TimeValue{timestamp=2021-01-18T08:00:51Z, value=75.964}, TimeValue{timestamp=2021-01-18T08:00:53Z, value=93.217}]Puedes ver que hay tres hilos diferentes trabajando aquí:
- main
- ForkJoinPool.commonPool-worker-3
- ForkJoinPool.commonPool-worker-5
Es interesante notar que, en esta ejecución específica, allOf(...).join() fue
llamado mucho antes de que se llamara al provider 2 y de que ambos resultados
fueran devueltos por los proveedores.
Tu output será ciertamente diferente ya que:
- el orden de ejecución de los hilos es no determinista
- los valores de los proveedores se generan aleatoriamente
Conclusión
¡Lo lograste! Ha sido un buen recorrido. Espero que haya sido entretenido. Dediqué bastante tiempo a esto cuando estaba intentando profundizar en algunos aspectos que me encontré en el trabajo. Te sugiero que hagas lo mismo cuando te encuentres con problemas que necesiten ser investigados más a fondo. Espero que te haya resultado útil.
Bonus

esta es mi venganza por todas las malas notas en matemáticas en la escuela.


Los time series data, también conocidos como time-stamped data, son una secuencia de datos indexados en orden temporal. Time-stamped son datos recopilados en diferentes momentos. Estos datos consisten típicamente en mediciones sucesivas realizadas desde la misma fuente a lo largo de un intervalo de tiempo y se utilizan para rastrear cambios a lo largo del tiempo.
Me gusta pensar en este movimiento como una especie de danza, y la encuentro sexy. Creo que I'm a creep, I'm a weirdo.